Advanced Heuistics
Advanced Heuristics
 By Fatemeh Bahrani, Rosta Roghani, Yasaman Shaykhan
By Fatemeh Bahrani, Rosta Roghani, Yasaman Shaykhan
By Fatemeh Bahrani, Rosta Roghani, Yasaman Shaykhan
Heuristic Functions
Definition: For systematic search in AI, it is common to use heuristic functions. These functions provide a guide to the status of the remaining path in each mode to the target mode. With such a function, our search will be smarter. A*, Hill climbing, Simmulated Annealing, and Beam Search are some of the most famous algorithms that use heuristics.
This function takes a state of the environment and estimates the shortest path of the node to the target and returns it. This function is one of the search criteria for selecting estimates of the cost of the route so that it succeeds in reaching the nearest goal. The better heuristic function is, the fewer mistakes we make and the faster we get the answer. The most common way that transfers problem information to a search operation is called a heuristic function, usually denoted by h (n).
Definition: For systematic search in AI, it is common to use heuristic functions. These functions provide a guide to the status of the remaining path in each mode to the target mode. With such a function, our search will be smarter. A*, Hill climbing, Simmulated Annealing, and Beam Search are some of the most famous algorithms that use heuristics.
This function takes a state of the environment and estimates the shortest path of the node to the target and returns it. This function is one of the search criteria for selecting estimates of the cost of the route so that it succeeds in reaching the nearest goal. The better heuristic function is, the fewer mistakes we make and the faster we get the answer. The most common way that transfers problem information to a search operation is called a heuristic function, usually denoted by h (n).
In the case of heuristic functions, two features are important; Being monotonic and admissible.
● Being “Admissible” means that the heuristic function underestimates the cost of reaching the goal from a node. The advantage of having such feature in A* (For example) is that if there is a path from s to a goal state, A* terminates by finding an optimal path.
● Being “Admissible” means that the heuristic function underestimates the cost of reaching the goal from a node. The advantage of having such feature in A* (For example) is that if there is a path from s to a goal state, A* terminates by finding an optimal path.
● Being “Monotonic” means that f values never decrease from node to descendants.
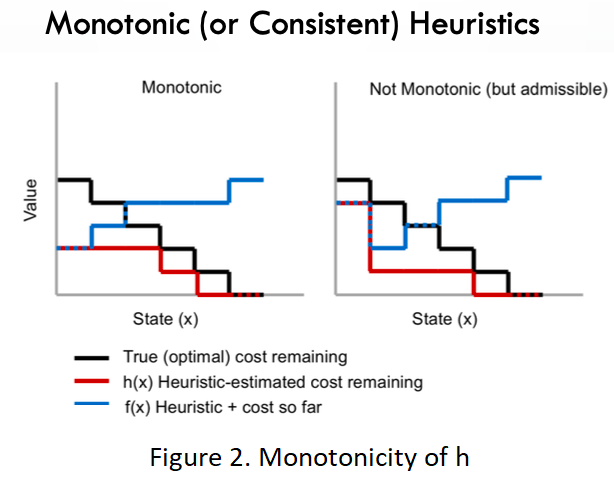
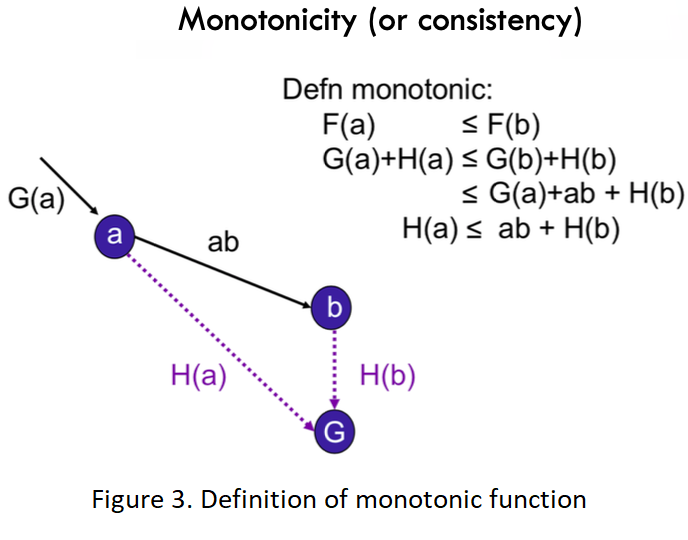
Note that being monotonic is a sufficient condition for being admissible. (Nonetheless, most admissible heuristics are also consistent.)
Proof: Like admissibility, being monotonic also helps to find an optimal path to the state it selects for expansion.
Like admissibility, being monotonic also helps to find an optimal path to the state it selects for expansion.
Proof:
Like admissibility, being monotonic also helps to find an optimal path to the state it selects for expansion.
How to make a heuristic function Monotonic (or Consistent):

In the case of Tree Search, only the condition of h being admissible is required. Two conditions are required for the h function in Graph Search: 1. being Admissible and 2. being Monotonic.
∗ Finding the optimal h (h∗) is difficult in some cases, and this is an important choice. The closer h is to h∗, the fewer nodes open. If h ≤ h*, it will find the optimal answer. If h and h∗ are equal, it only opens the path to the optimal answer. But if h > h∗ , it may not find the optimal answer.
Counterexample:
In the case of Tree Search, only the condition of h being admissible is required. Two conditions are required for the h function in Graph Search: 1. being Admissible and 2. being Monotonic.
∗ Finding the optimal h (h∗) is difficult in some cases, and this is an important choice. The closer h is to h∗, the fewer nodes open. If h ≤ h*, it will find the optimal answer. If h and h∗ are equal, it only opens the path to the optimal answer. But if h > h∗ , it may not find the optimal answer.
Counterexample:
8-puzzle; An Important Example:
Given a 3×3 board with 8 tiles (every tile has one number from 1 to 8) and one empty space. The objective is to place the numbers on tiles to match the final configuration using the empty space. We can slide four adjacent (left, right, above, and below) tiles into the empty space. For example: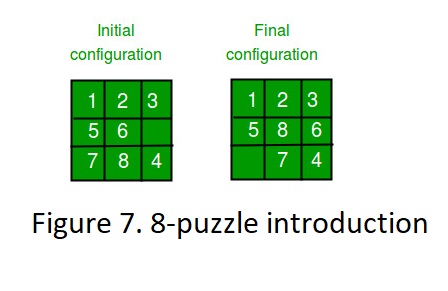 24-puzzle could be defined as well. (Size of the board is 5×5 instead of 3×3 and it has the same rules for moving.)
24-puzzle could be defined as well. (Size of the board is 5×5 instead of 3×3 and it has the same rules for moving.)
For more information, click here
Given a 3×3 board with 8 tiles (every tile has one number from 1 to 8) and one empty space. The objective is to place the numbers on tiles to match the final configuration using the empty space. We can slide four adjacent (left, right, above, and below) tiles into the empty space. For example:
24-puzzle could be defined as well. (Size of the board is 5×5 instead of 3×3 and it has the same rules for moving.)
For more information, click here
Heuristic Dominance
Now we are going to introduce a new concept that is used to compare the performance of two heuristic functions.
● If h2 ≥ h1 for all n (both admissable) then h2 dominates h1 → h2 is better for search
● Typical earch costs (average number of nodes axpanded) for 8-puzzle problem
d = 12 :
IDS = 3,644,035 nodes
A∗(h1) = 227 nodes
A∗(h2) = 73 nodes
d = 24 :
IDS = too many nodes
A∗(h1) = 39,135 nodes
A∗(h2) = 1,641 nodes
Now we are going to introduce a new concept that is used to compare the performance of two heuristic functions.
● If h2 ≥ h1 for all n (both admissable) then h2 dominates h1 → h2 is better for search
● Typical earch costs (average number of nodes axpanded) for 8-puzzle problem
d = 12 :
IDS = 3,644,035 nodes
A∗(h1) = 227 nodes
A∗(h2) = 73 nodes
d = 24 :
IDS = too many nodes
A∗(h1) = 39,135 nodes
A∗(h2) = 1,641 nodes
Heuristic function design constraint relaxation:
There are ways to improve a heuristic function. One of these ways is relaxation. In this method, we look for the answer in a space with fewer terms and conditions; and instead of minimizing the cost, we find the lower bound. As a result, it has become easier to solve.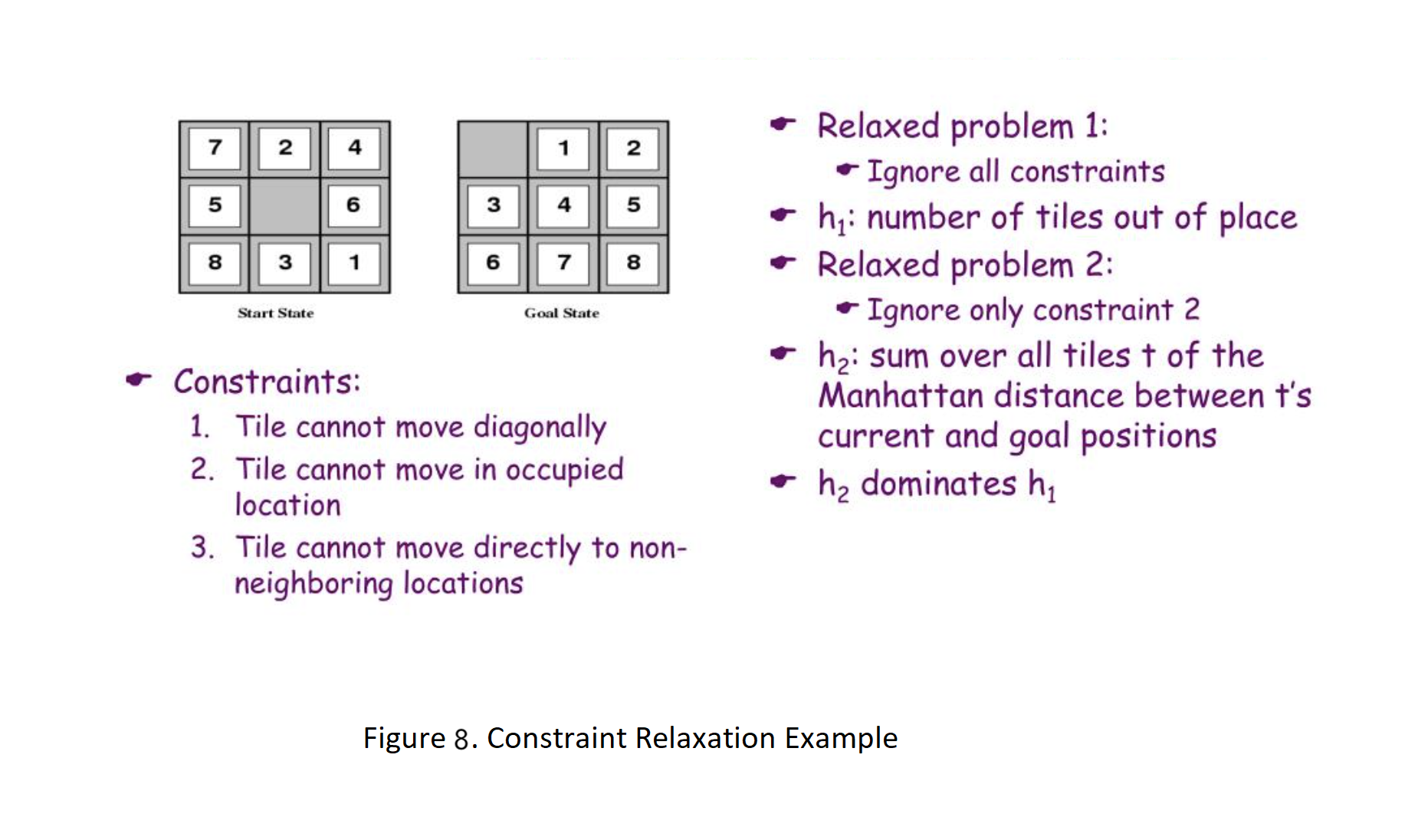 In general, admissible heuristic functions represent the cost of exact solutions to simplified or relaxed versions of the original problem (Pearl, 1984). For example, in a sliding tile puzzle (like 8-puzzle), to move a tile from position x to position y, x and y must be adjacent, and position y must be empty. By ignoring the empty constraint, we get a simplified problem where any tile can move to any adjacent position. We can solve any instance of this new problem optimally by moving each tile along the shortest path to its goal position, counting the number of moves made. The cost of such a solution is exactly the Manhattan distance from the initial state to the goal state. Since we removed a constraint on the moves, any solution to the original problem is also a solution to the simplified problem, and the cost of an optimal solution to the simplified problem is a lower bound on the cost of an optimal solution to the original problem. Thus, any heuristic derived in this way is admissible.
In general, admissible heuristic functions represent the cost of exact solutions to simplified or relaxed versions of the original problem (Pearl, 1984). For example, in a sliding tile puzzle (like 8-puzzle), to move a tile from position x to position y, x and y must be adjacent, and position y must be empty. By ignoring the empty constraint, we get a simplified problem where any tile can move to any adjacent position. We can solve any instance of this new problem optimally by moving each tile along the shortest path to its goal position, counting the number of moves made. The cost of such a solution is exactly the Manhattan distance from the initial state to the goal state. Since we removed a constraint on the moves, any solution to the original problem is also a solution to the simplified problem, and the cost of an optimal solution to the simplified problem is a lower bound on the cost of an optimal solution to the original problem. Thus, any heuristic derived in this way is admissible.
More Relaxed Heuristic Functions:
− Pattern Database Heuristics
− Linear Conflict Heuristics
− Gaschnig’s Heuristics
There are ways to improve a heuristic function. One of these ways is relaxation. In this method, we look for the answer in a space with fewer terms and conditions; and instead of minimizing the cost, we find the lower bound. As a result, it has become easier to solve.
In general, admissible heuristic functions represent the cost of exact solutions to simplified or relaxed versions of the original problem (Pearl, 1984). For example, in a sliding tile puzzle (like 8-puzzle), to move a tile from position x to position y, x and y must be adjacent, and position y must be empty. By ignoring the empty constraint, we get a simplified problem where any tile can move to any adjacent position. We can solve any instance of this new problem optimally by moving each tile along the shortest path to its goal position, counting the number of moves made. The cost of such a solution is exactly the Manhattan distance from the initial state to the goal state. Since we removed a constraint on the moves, any solution to the original problem is also a solution to the simplified problem, and the cost of an optimal solution to the simplified problem is a lower bound on the cost of an optimal solution to the original problem. Thus, any heuristic derived in this way is admissible.
More Relaxed Heuristic Functions:
− Pattern Database Heuristics
− Linear Conflict Heuristics
− Gaschnig’s Heuristics
Pattern Database:
We can consider a subset of the search space and consider others as "don't care". In this case, the interaction between the cells inside this subset is considered and the independence is reduced. The function h can then be obtained by combining "h"s from different subsets (search space separation). Pattern databases are for exploratory estimation of storing state-to-target distances in state space. Their effectiveness depends on the choice of basic patterns. If it is possible to divide the subsets into separate subsets so that each operator only affects the subsets in one subset, then we can have a more acceptable exploration performance. We used this method to improve performance in 15-puzzles with a coefficient of more than 2000 and to find optimal solutions for 50 random samples of 24-puzzles.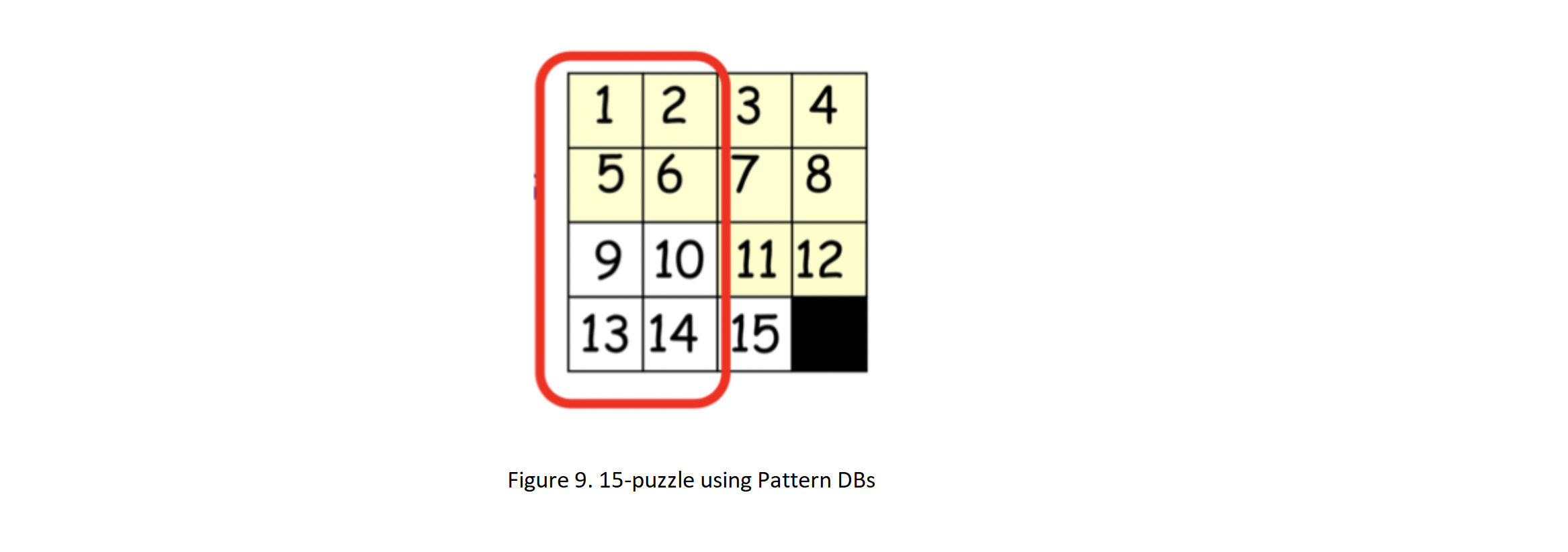 How do we combine the “h” s of the separated subset of state space?
− MAX: Which has diminishing.
How do we combine the “h” s of the separated subset of state space?
− MAX: Which has diminishing.
− ADD: In this case, the limitation is removed and it is admissible.
Using a Pattern Database helps us solve many problems, but it is flawed in very large cases and is not scalable.
Drawbacks of Pattern DBs:
● Since we can only take max
● Diminishing returns on additional DBs
● Consider bigger problem instances.
● Subproblems should be small to be scalable.
● If hi(n) from each database is at most x, then maxi hi would be at most x.
● Would like to be able to add values
We can consider a subset of the search space and consider others as "don't care". In this case, the interaction between the cells inside this subset is considered and the independence is reduced. The function h can then be obtained by combining "h"s from different subsets (search space separation). Pattern databases are for exploratory estimation of storing state-to-target distances in state space. Their effectiveness depends on the choice of basic patterns. If it is possible to divide the subsets into separate subsets so that each operator only affects the subsets in one subset, then we can have a more acceptable exploration performance. We used this method to improve performance in 15-puzzles with a coefficient of more than 2000 and to find optimal solutions for 50 random samples of 24-puzzles.
How do we combine the “h” s of the separated subset of state space?
− MAX: Which has diminishing. − ADD: In this case, the limitation is removed and it is admissible.
Using a Pattern Database helps us solve many problems, but it is flawed in very large cases and is not scalable.
Drawbacks of Pattern DBs:
● Since we can only take max
● Diminishing returns on additional DBs
● Consider bigger problem instances.
● Subproblems should be small to be scalable.
● If hi(n) from each database is at most x, then maxi hi would be at most x.
● Would like to be able to add values
Disjoint of Pattern DBs:
What if we make patterns be disjoint sets? Can we take summation of heuristics by pattern DBs as an admissible heuristic? In order to fix this, take number of moves made to the specified tiles as hi instead.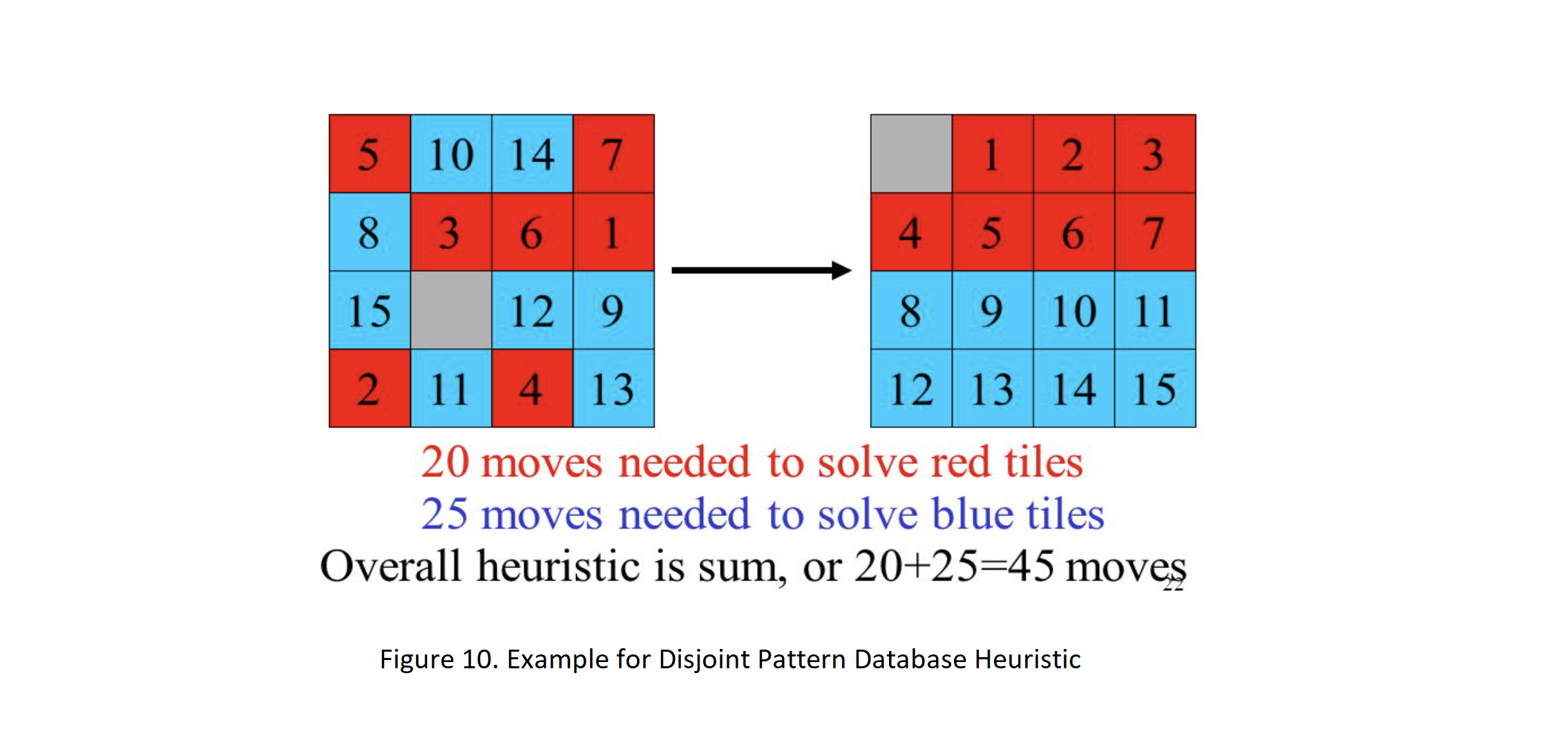 Why does summation result in an admissible heuristic in that case?
Why does summation result in an admissible heuristic in that case?
Proof:
h∗(s0) = min n1 + ... + nn
s.t. sn ∈ G, ai∈ Asi, si∈ S, s1 = s0
si + 1 = succ(si,ai)
ni = |{ak | sk(ak(1)) ∈ Pi}|
Asi = {(j,k)| 1 ≤ j ≤ 8 , 1 ≤ k ≤ 9 , j ∈ Nempty(si), k ∈ Iempty(si)}
⇒
h∗(s0) ≥ min n1 + ... + min nn
s.t. sn ∈ G, ai∈ Asi, si∈ S, s1 = s0
si + 1 = succ(si,ai)
ni = |{ak | sk(ak(1)) ∈ Pi}|
Asi = {(j,k)| 1 ≤ j ≤ 8 , 1 ≤ k ≤ 9 , j ∈ Nempty Manhattan Dist. is a trivial example of a disjoint DBs, where each group contains only a single tile. As a general rule, when partitioning the tiles, we want to group tiles that are near each other in the goal state, since these tiles will interact the most with one another. Using this method, the 15-puzzle problem is solved 2000 times and the 24-puzzle problem is 12 million times faster
What if we make patterns be disjoint sets? Can we take summation of heuristics by pattern DBs as an admissible heuristic? In order to fix this, take number of moves made to the specified tiles as hi instead.
Why does summation result in an admissible heuristic in that case?
Proof:
s.t. sn ∈ G, ai∈ Asi, si∈ S, s1 = s0
si + 1 = succ(si,ai)
ni = |{ak | sk(ak(1)) ∈ Pi}|
Asi = {(j,k)| 1 ≤ j ≤ 8 , 1 ≤ k ≤ 9 , j ∈ Nempty(si), k ∈ Iempty(si)}
⇒
h∗(s0) ≥ min n1 + ... + min nn
s.t. sn ∈ G, ai∈ Asi, si∈ S, s1 = s0
si + 1 = succ(si,ai)
ni = |{ak | sk(ak(1)) ∈ Pi}|
Asi = {(j,k)| 1 ≤ j ≤ 8 , 1 ≤ k ≤ 9 , j ∈ Nempty Manhattan Dist. is a trivial example of a disjoint DBs, where each group contains only a single tile. As a general rule, when partitioning the tiles, we want to group tiles that are near each other in the goal state, since these tiles will interact the most with one another. Using this method, the 15-puzzle problem is solved 2000 times and the 24-puzzle problem is 12 million times faster
Resources
- https://cse.iitkgp.ac.in/~pallab/ai.slides/lec3a.pdf
- www.cs.stackexchange.com/questions/63481/how-does-consistency-imply-that-a-heuristic-is-also-admissible
- www.courses.cs.washington.edu/courses/cse473/12sp/slides/04-heuristics.pdf
- www.sciencedirect.com/science/article/pii/S0004370201000923
- https://www.geeksforgeeks.org/8-puzzle-problem-using-branch-and-bound/
- www.researchgate.net/publication/222830183_Disjoint_pattern_database_heuristics
- www.aaai.org/Papers/JAIR/Vol22/JAIR-2209.pdf
- www.link.springer.com/chapter/10.1007/978-3-540-74128-2_3
- www.stackoverflow.com/questions/46554459/intuitively-understanding-why-consistency-is-required-for-optimality-in-a-searc
Authors

Fatemeh Bahrani
Author

Yasaman Shaykhan
Author
Rosta Roghani
Author

Zeinab Sadat Saghi
Supervisor